一、问题描述:
因为项目中使用到了Zookeeper,所以我自己找了些关于zk的资料学习了一下。在异步创建节点的过程中,抛出了如下问题:
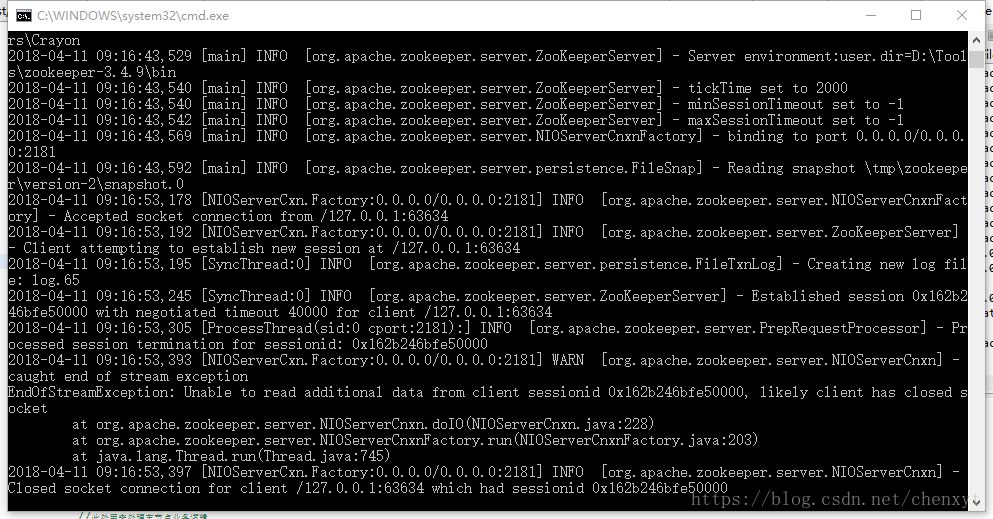
异步创建节点的时候总是闪退,然后服务端报错 Unable to read additional data from client sessionid 0x162b246bfe50000, likely client has closed socket ,我们先看下代码 这里我把同步跟异步的代码一起贴了出来便于学习
1 | package zk.zkTest; |
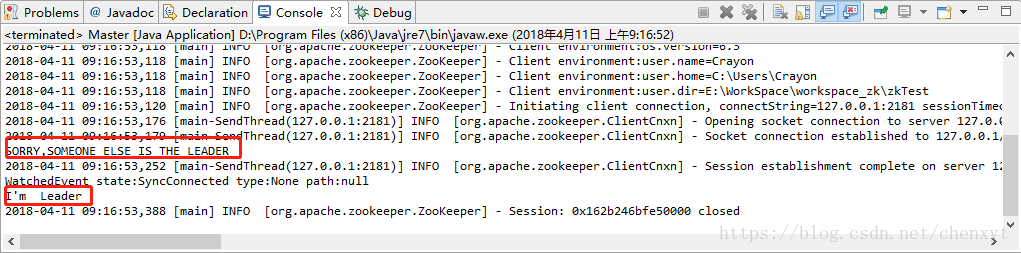
我们看下运行之后的控制台信息:
二、解决方案:
从上边控制台的信息可以看出 if/else的判断发生在了异步回调之前,并且打印了最后一行日志Session closed
所以这里抛错的原因是:没有等待异步通知的响应信息,就提前关闭了连接。解决方法就是在if/else之前延时等待,或者设置变量等待异步通知返回结果之后再进行if/else判断。
网上还有很多关于这个错误的解决方案,场景不同,但大多数的原因都是因为网络中断,有的可能是超时时间不够,我这里的原因是在异步通知返回结果之前就人为的结束了连接。









































































